Boomtime, the 69 day of Discord in the YOLD 3176
Övergång till UTF-8
Jag har äntligen tagit steget till UTF-8. Antagligen är jag sist i Sverige med det. Jag körde visserligen UTF-8 på Plan 9 redan 1995, för Plan 9 kunde ju inte något annat, men jag har varit kvar i en Latin 1-locale på unixar ända tills nu.
Orsaken är nog mest feghet, tror jag. Jag har känt mig otrygg med vad som skall hända med alla filer (och en del filnamn!) jag har i ISO 8859-1. Kommer de program jag använder att ens tolerera dem om jag byter till en locale som säger att jag använder UTF-8?
Använder jag UTF-8 kan jag dessutom inte längre att kunna arbeta obehindrat i konsolläge i FreeBSD, eftersom konsollen ännu inte kan UTF-8. Det är i och för sig ett mindre problem jämfört med de många andra jag föreställde mig att jag skulle få.
Nu gjorde jag i alla fall härom dagen
export LANG=en_US.UTF-8
och det verkar fungera för det mesta.
Jag fick göra en del konverteringar, men mycket av det dagliga arbetet hjälper Emacs mig med. Emacs kan automagiskt känna igen en fil i Latin 1 och nästan vilken annan kodning som helst om jag får tro manualen. Det fungerar faktiskt förvånansvärt bra för det mesta. Emacs fortsätter att spara filen i den kodningen så länge jag inte stoppar in tecken som inte kan representeras. Sedan jag sist försiktigt experimenterade med det här har Emacs blivit mycket bättre på Unicode-hantering.
Jag var däremot inte alls lika nöjd med hur xterm klarade sig. Jag vill förstås att min terminalemulator när den dyker på en kodpunkt som inte finns definierad i defaultfonten skall försöka hitta en annan font som kan visa dem, men det fungerade inte. Trevligt nog hade jag på en hackjunta nyligen blivit visad rxvt-forken rxvt-unicode, så jag installerade den och experimenterade lite. Jag är mycket nöjd med resultatet. Jag borde inte ha blivit förvånad, men allt fungerar också i en screen över ssh.
Jag fick några trevliga X-resurser för urxvt från bland annat Anders Waldenborg och kombinerat med mina gamla xterm-resurser blev det här resultatet:
urxvt.background: #000000 urxvt.foreground: gray90 urxvt.color0: black urxvt.color1: IndianRed urxvt.color2: palegreen urxvt.color3: goldenrod urxvt.color4: SteelBlue3 urxvt.color5: PaleVioletRed urxvt.color6: cyan3 urxvt.color7: gray90 urxvt.color8: gray30 urxvt.color9: red urxvt.color10: cyan4 urxvt.color11: DarkOrange urxvt.color12: RoyalBlue3 urxvt.color13: HotPink urxvt.color14: VioletRed urxvt.color15: white urxvt.colorBD: #ffffff ! Amber: urxvt.cursorColor: #ff7f24 urxvt.highlightColor: dimgrey urxvt.scrollBar: false urxvt.saveLines: 512 urxvt.secondaryScroll: true urxvt.termName: xterm-88color urxvt.font: FIXFONT urxvt.visualBell: true
där FIXFONT är definierad som
#define FIXFONT -xos4-terminus-medium-r-normal--16-160-72-72-c-80-iso10646-1
Resten fungerar väl med defaultinställningarna, tycker jag.
När jag väl bytt började jag förstås leka med andra saker också, till
exempel trådmarkeringen i Gnus som jag nu plötsligt kan ha roligare
tecken i, oavsett om jag kör min Emacs som X-tillämpning eller i en
urxvt. Från min .gnus.el:
;;; Make threading look pretty with Unicode line-drawing. (setq-default gnus-sum-thread-tree-single-indent " " gnus-sum-thread-tree-false-root "" gnus-sum-thread-tree-root "┌ " gnus-sum-thread-tree-vertical "│" gnus-sum-thread-tree-leaf-with-other "├─>" gnus-sum-thread-tree-single-leaf "└─>" gnus-sum-thread-tree-indent "")
Det ser ut så här:
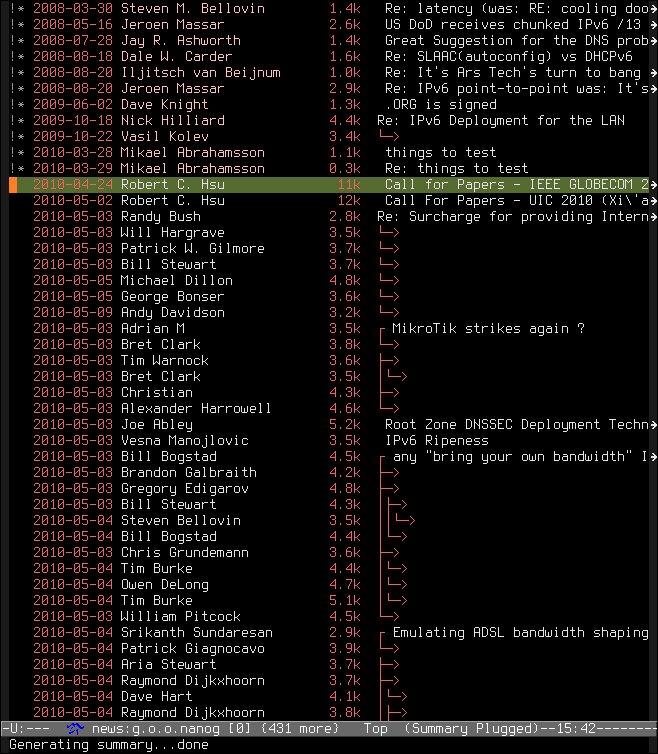
Dessutom stoppade jag in utf-8 och utf-16 i den här listan:
(setq mm-body-charset-encoding-alist
'((utf-16 . 8bit)
(utf-16be . 8bit)
(utf-16le . 8bit)
(utf-8 . 8bit)
(iso-8859-1 . 8bit)))
för att vara någorlunda säker på att vanliga brev skrivna med Unicode inte skickas i BASE64 eller något annat hemskt som inte är så lätt att greppa i.
Å andra sidan finns specialfallet PGP-signerade brev. Som bekant kan det hända att vägen MUA-MTA-MTA-MUA inte alltid är helt åttabitarsren och det kan, men måste inte, förekomma konverteringar på vägen. Om mitt fina åttabitarsbrev blivit konverterat till Quoted (un)Printables på vägen så validerar förstås inte längre min PGP-signatur hos mottagaren. Misär!
Alltså behövs en liten revidering, speciellt vad gäller just signerade brev i klartext:
(setq mm-content-transfer-encoding-defaults '(("text/.*" 8bit) ("message/rfc822" 8bit) ("application/emacs-lisp" 8bit) ("application/x-emacs-lisp" 8bit) ("application/x-patch" 8bit) ("multipart/signed" qp) ; Obs! (".*" base64)))
Kanske är det fegt att säga att allt annat skall kodas som BASE64. Jag vet inte. Jag måste nog utföra lite experiment för att bli trygg med något annat där.
I Emacs i övrigt hakade jag också in det här för att kunna knappa in
några vanliga tecken som annars inte finns på mitt tangentbord (ur min
.emacs.el):
; em-dash (define-key global-map [(meta \-)] "—") ; en-dash (define-key global-map [(meta \_)] "–") ; quotes (define-key global-map [(meta \!)] "“") (define-key global-map [(meta \")] "”")
Det var värre med mina websidor. De serveras av webservern thttpd som av någon anledning alltid skickar med ”charset=foo” för MIME-typerna ”text/*” där ”foo” är vad du sagt i konfigurationen eller som default iso-8859-1. Det är alltså inte beroende på vad filerna faktiskt råkar vara kodade i!
Jag är mycket nöjd med thttpd i övrigt, men just det här var bara korkat. Tyvärr går just detta inte att konfigurera bort, så det slutade med en omkompilering efter följande ändring i thttpd 2.25b:
--- mime_types.txt~ 2003-10-26 18:00:45.000000000 +0100 +++ mime_types.txt 2010-05-18 23:11:14.000000000 +0200 @@ -14,6 +14,7 @@ asc text/plain asf video/x-ms-asf asx video/x-ms-asf +atom application/atom+xml au audio/basic avi video/x-msvideo bcpio application/x-bcpio @@ -52,8 +53,8 @@ gtar application/x-gtar hdf application/x-hdf hqx application/mac-binhex40 -htm text/html; charset=%s -html text/html; charset=%s +htm text/html +html text/html ice x-conference/x-cooltalk ief image/ief iges model/iges @@ -161,7 +162,7 @@ tr application/x-troff tsp application/dsptype tsv text/tab-separated-values -txt text/plain; charset=%s +txt text/plain ustar application/x-ustar vcd application/x-cdlink vrml model/vrml
Jag tog alltså helt enkelt bort att ”charset” skickas med överhuvudtaget i innehållsdeklarationen. Dessutom passade jag på att lägga till en MIME-typ för Atom-flöden, som ni ser. (Förresten validerar nu Atom-flödet enligt W3C Feed Validator, men det är nog ett annat bloginlägg.)
Efter den här förändringen litar jag dessvärre på att filerna som serveras som MIME-typerna ”text/*” själva skall tala om vad de har för teckenuppsättning. Det gör inte alla än, men i de browsers jag testat (w3m, Lynx, Firefox och Internet Explorer 7), så verkar den inbyggda heuristiken för att känna igen teckenuppsättningar ändå fungera ganska bra.
Jag ändrade också på mitt lilla script för att generera websidor, mdn, så att den deklarerar teckenuppsättning som UTF-8 i stället för ISO-8859-1. Samma ändring gjorde jag i Blosxom som genererar den här bloggen.
Jag skrev ett throw away-script för att konvertera alla inlägg i bloggen till UTF-8. Tyvärr var det lite buggigt, så det blev lite handpåläggning på några inlägg i alla fall. Hade jag inte gjort någon konverting hade det nästa gång jag skriver ett inlägg (nu, alltså!) blivit en intressant blandning av Latin 1 och UTF-8, med bara en innehållsdeklaration, åtminstone i HTML-filen.
En del andra filer konverterade jag med hjälp av iconv och passade i
en del fall på att dessutom börja använda min nya Markdown-baserade
märkning. Jag byter alltså långsamt från min gamla hackade txt2tags till
mitt eget mdn.
Slutsatsen är ändå att bytet till UTF-8 gått ganska bra, i alla fall än så länge. Jag får nog tacka Emacs och urxvt mest för det, tror jag.
Jag slutar med lite roande läsning i form av några brev från Rob Pike om tillblivelsen av UTF-8 som Marcus Kuhn sparat:
http://www.cl.cam.ac.uk/~mgk25/ucs/utf-8-history.txt
サヨウナラ,
MC
(Sayōnara, alltså. Jag kan inte ens lite japanska, men det är ju ett kul test av UTF-8.)